Diferencia entre revisiones de «Modelos epidemiológicos (Grupo 11A)»
(→Estudio de poblaciones mediante el método de Runge-Kutta) |
(→Análisis con parámetros variables) |
||
| Línea 197: | Línea 197: | ||
----------------------- | ----------------------- | ||
| − | - | + | G11-5.1.png |
----------------------- | ----------------------- | ||
Revisión del 00:46 5 mar 2015
| Trabajo realizado por estudiantes | |
|---|---|
| Título | Modelos epidemiológicos. Grupo 11-a |
| Asignatura | Ecuaciones Diferenciales |
| Curso | Curso 2014-15 |
| Autores | Jorge Cimorra Arche, Alejandro Ayala Alcaraz, Luis Díez, Ana Cristina Fernandez Delgado, Dolores Ruiz Mirón |
| Este artículo ha sido escrito por estudiantes como parte de su evaluación en la asignatura | |
Contenido
1 PÁGINA EN CONSTRUCCIÓN
2 Interpretación de los parámetros
Tenemos el modelo epidemiológico definido a continuación:
[math]\frac{dS}{dt}=-aSI[/math]: [math]\frac{dI}{dt}=aSI-bI-cI[/math]
Siendo:
- S: Población susceptible de infectarse por la enfermedad
- I: Población infectada por la enfermedad
- a: Parámetro de la interacción entre el número de individuos de ambas clases.
- b: Parámetro que representa el número de fallecidos a causa de la enfermedad.
- c: Parámetro que representa el numero de personas que han superado la enfermedad.
La primera ecuación representa la variación de la población susceptible de contraer la enfermedad en función del
tiempo. Vemos que es una función decreciente debido al signo negativo que acompaña al parámetro [math]a[/math]. Esto implica que la población susceptible de este modelo siempre va a disminuir siendo su máximo el valor inicial [math]S_0[/math] . La función es dependiente tanto de la población susceptible como de la infectada. Al estar multiplicadas ambas variables se convierte en una ecuación no lineal, factor determinante a la hora de resolver el sistema.
La segunda ecuación representa la variación de la población infectada con respecto del tiempo. Podemos estudiarla en dos partes dividiéndola en una no lineal (análoga a la primera ecuación) y la parte lineal que tan solo depende de los infectados ([math]I[/math]). La primera parte es dependiente de nuevo del parámetro [math]a[/math] con signo positivo lo que hace crecer el número de infectados. Por el contrario, la parte lineal varía con los parámetros [math]b[/math] y [math]c[/math]. En este caso el signo es negativo ajustándose a la realidad pues representan el número de muertes y de curas.
El número de infectados vemos que aumentará o disminuirá según la relación que exista entre los parámetros [math]a[/math], [math]b[/math] y
[math]c[/math] y el número variable de infectados y susceptibles.
3 Estudio de poblaciones mediante el método de Runge-Kutta
Realizaremos varias simulaciones con diferentes valores de las poblaciones iniciales de infectados y susceptibles, el tiempo del estudio y el numero de intervalos. Tomamos los mismos valores de los parámetros que en el apartado anterior: [math]a = 0.003 , b = 0.3 , c = 0.01[/math]
Los datos de poblaciones iniciales los nombraremos como [math]S(1)[/math] para los individuos susceptibles e [math]I(1)[/math] para los infectados. El tiempo de estudio lo indica la variable [math]tN[/math] y el paso la variable [math]h[/math].
Aplicamos el método Runge-Kutta y lo programamos en Octave UPM. Escribimos el código una sola vez. Para sacar todas las gráficas de los diferentes modelos solo hay que cambiar los valores de las poblaciones iniciales, tiempo y paso.
clear all
%Valores del tiempo
t0 = 0;
tN = 40;
h = 0.1;
N = round((tN-t0)/h);
t = t0:h:tN;
%Vectores que contendrán la solución
S = zeros(1,N+1);
I = zeros(1,N+1);
%Valores iniciales
S(1) = 800;
I(1) = 20;
%Valores de los parámetros
a = 0.003;
b = 0.3;
c = 0.01;
%Bucle para sacar la componente i+1 de cada vector desde la primera hasta la N
for i = 1:N
K1 = -a*S(i)*I(i);
K2 = -a*S(i)*I(i) + 1/2*K1*h;
K3 = -a*S(i)*I(i) + 1/2*K2*h;
K4 = -a*S(i)*I(i) + K3*h;
S(i+1) = S(i) + h/6*(K1+2*K2+2*K3+K4);
L1 = (a*S(i)*I(i)) -I(i)*(b+c);
L2 = (a*S(i)*I(i)) -I(i)*(b+c) + 1/2*L1*h;
L3 = (a*S(i)*I(i)) -I(i)*(b+c) + 1/2*L2*h;
L4 = (a*S(i)*I(i)) -I(i)*(b+c) + L3*h;
I(i+1) = I(i) + h/6*(L1+2*L2+2*L3+L4);
end
%Gráficas
hold on
plot (t,S,'-') %Población de sanos (azul)
plot (t,I,'-r') %Población de infectados (rojo)
hold off


En la gráfica superior se observa que al aumentar mucho los valores de la población el método no funciona. Es obvio, por ejemplo, que no puede haber poblaciones negativas ni existir las variaciones que se muestran en la gráfica. Esto es debido a que el paso es demasiado grande y en el bucle al haber números grandes también en la operaciones dan un error que provoca resultados incorrectos. Para solucionar esto simplemente disminuimos el paso a [math]h=0.01[/math] para analizar una mayor cantidad de intervalos y la nueva gráfica sale con la forma correcta. Añadimos también las gráficas con pasos [math]h=0.001[/math] y [math]h=0.0001[/math] y vemos la variacion entre ellas es mínima.
.png)
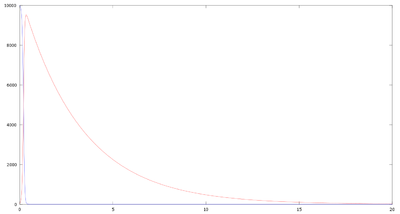
Hacemos un tercer análisis variando de nuevo las poblaciones, el tiempo de estudio y bajaremos el valor del parámetro [math]a[/math]. En los casos anteriores toda la población susceptible acababa infectada y posteriormente la población infectada también llegaba a 0. En este caso vemos que el parámetro [math]a[/math] que es el de contagio, junto con los datos de las poblaciones iniciales no consiguen que toda la población susceptible sea infectada antes de que la población infectada desaparezca; por lo que cuando esta desaparece la población de susceptibles se mantiene constante. Lo vemos en la gráfica inferior:

Utilizamos los métodos de Euler y Runge-Kutta porque son métodos explícitos, es decir, que para calcular el valor del termino [math]i+i[/math] solo se necesitan los valores de los términos [math]i[/math] anteriores. por el contrario, en los métodos implícitos para calcular el valor [math]i+1[/math] se necesitan los propios valores [math]i+1[/math] lo que conlleva a despejar manualmente los parámetros que se buscan, lo que en muchos casos es complicado o incluso imposible.
4 Análisis con parámetros variables
En este apartado utilizaremos el método de Heun para solucionar el mismo problema, pero le añadiremos unas pequeñas variaciones.
1. Cambiamos los valores de las poblaciones iniciales haciendo que en inicio los susceptibles sean 1600 y los infectados 40.
2. El parámetro de contagio 'a' será variable con el tiempo con valor: [math]a=0.003/1+t[/math] Esto significa que para el momento inicial tendrá un valor de 0.003; pero al ser el denominador negativo según avance el tiempo se ira haciendo cada vez mas pequeño; es decir, que cuanto mas avance el tiempo se tendrán menos posibilidades de ser infectado en el contacto de las dos poblaciones. Matemáticamente esto significa que el primer sumando de ambas ecuaciones, que es en el que interviene [math]a[/math], se hará cada vez menor, por lo que [math]S[/math] decrecerá mas lentamente (al tener signo negativo) e [math]I[/math] crecerá mas lentamente (al tener signo positivo).
El código utilizado y los resultados obtenidos son los siguientes.
clear all
%Valores del tiempo
t0 = 0;
tN = 40;
h = 0.1;
N = round((tN-t0)/h);
t = t0:h:tN;
%Vectores que contendrán la solución
S = zeros(1,N+1);
I = zeros(1,N+1);
%Valores iniciales
S(1) = 1600;
I(1) = 40;
%Valores de los parámetros
a = zeros(1,N+1);
a(1) = 0.003/(1+t0);
b = 0.3;
c = 0.01;
%Bucle para sacar la componente i+1 de cada vector desde la primera hasta la N
for i = 1:N
a(i+1) = 0.003/(1+t(i));
K1 = -a(i)*S(i)*I(i);
K2 = -a(i)*S(i)*I(i) + K1*h;
S(i+1) = S(i) + h/2*(K1+K2);
L1 = (a(i)*S(i)*I(i)) -I(i)*(b+c);
L2 = (a(i)*S(i)*I(i)) -I(i)*(b+c) + L1*h;
I(i+1) = I(i) + h/2*(L1+L2);
end
%Gráficas
hold on
plot (t,S,'-')
plot (t,I,'-r')
hold off
G11-5.1.png
Como vemos, al disminuir el ratio de contagio conseguimos que parte de la población sana no se infecte; y cuando esta desaparece por culpa de los términos [math]-bI[/math] y [math]-cI[/math], la población sana se mantiene constante. Si al contrario de esto el parámetro [math]a[/math] tuviera un denominador menor que 1, cada vez el riesgo de contagio seria mayor y la disminución de población sana y aumento de los infectados sería mucho mas rápido.
5 Evaluación de un parámetro
En este apartado se nos propone el problema de ajustar nuestra solución a un resultado de otro experimento anterior, variando el parámetro [math]a[/math] para ver que valor hace que el maximo de infectados se de en el quinto dia o lo mas cercano posible. A continuacion escribimos el codigo que resuelve el problema.
clear all
%Valores del tiempo
t0 = 0;
tN = 40;
h = 0.1;
N = round((tN-t0)/h);
t = t0:h:tN;
%Vectores que contendrán la solución
S = zeros(1,N+1);
I = zeros(1,N+1);
%Valores iniciales
S(1) = 1600;
I(1) = 40;
%Valores de los parámetros
a = 0.0005:10^-4:0.002;
b = 0.3;
c = 0.01;
TMAX = zeros(1,length(a));
%Bucle para sacar la componente i+1 de cada vector desde la primera hasta la N
for j = 1:16
for i = 1:N
K1 = -a(j)*S(i)*I(i);
K2 = -a(j)*S(i)*I(i) + K1*h;
S(i+1) = S(i) + h/2*(K1+K2);
L1 = (a(j)*S(i)*I(i)) -I(i)*(b+c);
L2 = (a(j)*S(i)*I(i)) -I(i)*(b+c) + L1*h;
I(i+1) = I(i) + h/2*(L1+L2);
if i>1 && I(i+1)<I(i) && I(i)>I(i-1)
TMAX(j) = t(i);
end
end
end
dist = (abs(TMAX-5));
[valormin,posmin] = min(dist);
a = a(posmin)
Para solucionar el problema dado nos hemos basado en los datos y el método del problema anterior; y hemos sacado la solución a base de encadenar sucesivos bucles.
Primeramente hemos puesto un bucle tipo [math]for[/math] que nos elije un primer valor de [math]a[/math] y seguido un segundo bucle [math]for[/math] que resuelve el problema para ese valor del parámetro. antes de salir de este bucle, con un tercer bucle tipo [math]if[/math] evaluamos el valor máximo de la población de infectados e introducimos el tiempo correspondiente en el vector llamado [math]TMAX[/math]. Después cogemos el siguiente valor de [math]a[/math] a evaluar y repetimos el proceso hasta conseguir que el vector [math]TMAX[/math] tenga todos los tiempos cuando se da la mayor población de infectados para todos los valores del parámetro. Por ultimo solo queda ver cual es el mas cercano a 5. Para ello hacemos el valor absoluto de la resta entre el valor obtenido y 5 y sacamos la componente donde ese valor distancia es mínimo. Para terminar evaluamos [math]a[/math] para esa posición consiguiendo la solución para el problema planteado